
Governed AI systems are AI systems that are observable, auditable, human-supervised, rollback-ready, and owned by your team. Every decision the AI makes can be traced, questioned, and reversed. Governance is not a compliance checkbox — it is the structural difference between an AI project that delivers compounding value and one that becomes an expensive line item nobody wants to own.
Here is a number that should concern every executive investing in artificial intelligence: according to Gartner research, roughly 85% of enterprise AI projects never make it to production. They stall in proof-of-concept, get shelved after a pilot, or quietly disappear from the roadmap. The reason is rarely the model itself. The reason is almost always that organisations build AI without governed AI systems around it — or, more accurately, without the governance architecture that makes production viable.
We have spent years building AI systems for organisations across regulated industries, and the pattern is always the same. The teams that treat governance as an afterthought end up rebuilding from scratch. The teams that design governance into the system from day one ship faster, scale further, and sleep better. This article explains what governed AI actually means, why it matters more than model selection, and how to build it into your own AI programmes.
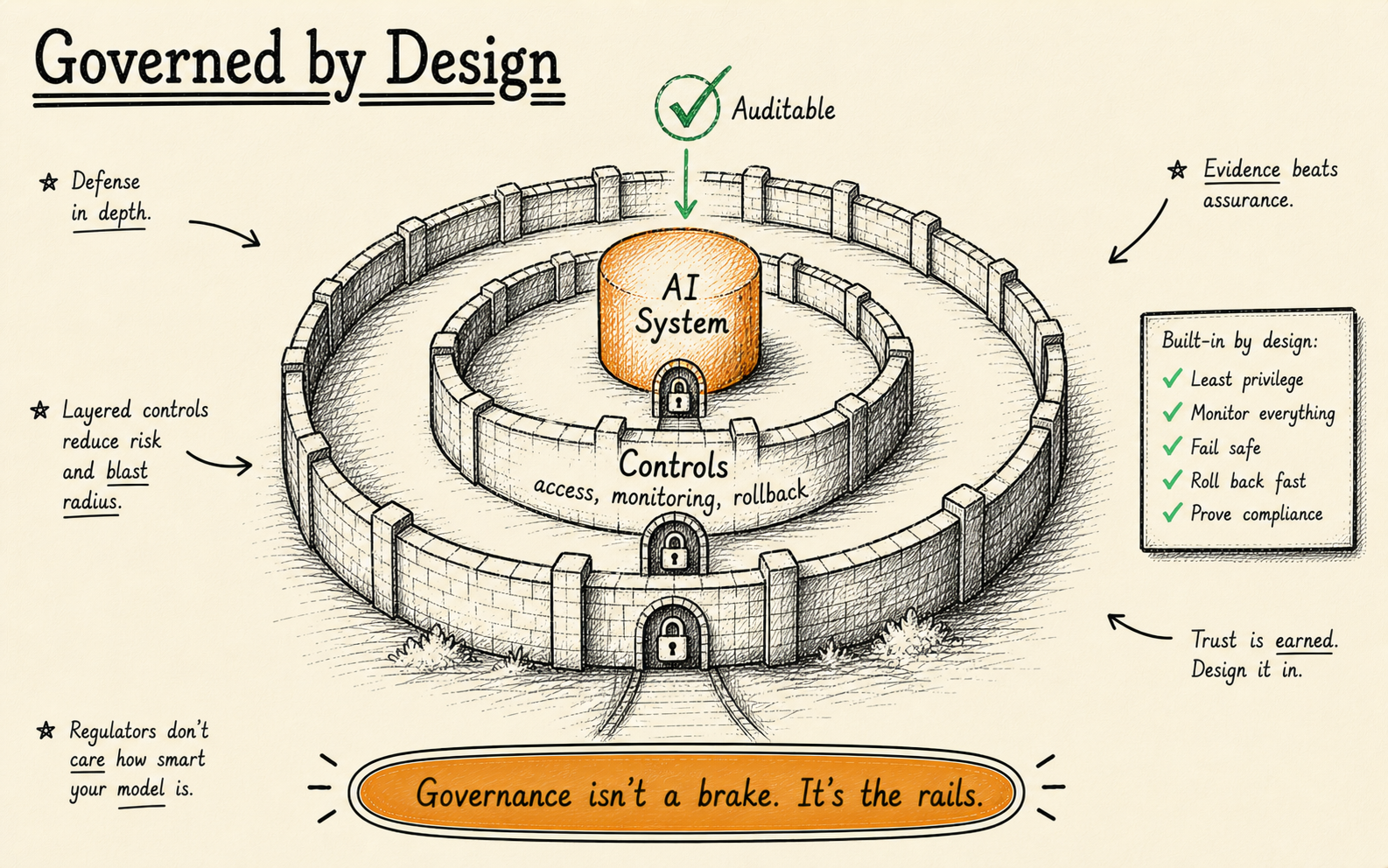
What does “governed AI” actually mean?
Governed AI means AI systems that are observable, auditable, human-supervised, rollback-ready, and owned by your team — all five properties simultaneously. Remove any one of these properties and you do not have governance; you have a liability. The term gets thrown around in boardrooms and vendor pitches, usually without a precise definition. So let us be specific about what each of these five properties requires in practice.
Observable. You can see what the AI decided and why it decided it. This is not the same as having a dashboard that shows throughput metrics. Observability means you can inspect a specific decision — this invoice was flagged, this document was classified, this recommendation was surfaced — and trace the reasoning chain that produced it. If you cannot answer “why did the AI do that?” within minutes, your system is not observable. It is a black box with a pretty front end.
Human-in-loop. High-stakes decisions require human approval before they execute. This does not mean a human reviews every single output. That defeats the purpose of automation. It means the system knows which decisions are high-stakes and routes them to the right person at the right time. A document classification system might auto-process 95% of inputs but escalate the remaining 5% — the ambiguous ones, the ones that fall outside training distribution — to a human reviewer. The boundary between autonomous and escalated is explicit, documented, and adjustable.
Auditable. Every action the AI takes is logged with enough context to reconstruct the decision later. This matters for regulatory compliance, but it matters even more for debugging. When something goes wrong — and something always goes wrong — you need a full trail: what data went in, what model version processed it, what confidence score it produced, what action it triggered, and who (human or system) approved it. Without an audit trail, incident response becomes guesswork.
Rollback-ready. If the AI breaks, you can revert. This sounds obvious, but most enterprise AI deployments have no rollback plan. The model is updated, the old version is discarded, and if the new version produces worse results, the team scrambles to retrain or hotfix. A governed system maintains versioned models, versioned decision logic, and versioned data pipelines. Rolling back is a button press, not a project.
Owned. Your team runs it. You are not dependent on a vendor’s API, a vendor’s infrastructure, or a vendor’s timeline for critical fixes. Ownership does not mean you build everything from scratch — it means you have the knowledge, access, and authority to operate, modify, and shut down the system without calling someone else’s support line. Vendor lock-in is the opposite of governance. If you cannot explain how your AI system works without calling the vendor, you do not own it.
These five properties — observable, human-in-loop, auditable, rollback-ready, and owned — form the foundation of what we mean when we talk about governed AI systems. They are not aspirational. They are architectural requirements.
Why most enterprise AI projects fail — and governed AI systems are the answer
Most enterprise AI projects fail because organisations focus on the model and neglect the governance systems around it — data pipelines, access controls, monitoring, escalation workflows, and rollback procedures. The 85% failure rate is not a mystery. It is a predictable outcome of how most organisations approach AI adoption.
The typical pattern looks like this: a team identifies an AI use case, selects a model or platform, builds a proof-of-concept that works impressively in a demo environment, and then attempts to put it into production. At that point, everything stalls. The security team wants to know what data the model accesses. The compliance team wants an audit trail. The operations team wants to know what happens when the model fails. The business owner wants to know who is responsible when the AI makes a bad decision. Nobody planned for any of this because everyone was focused on the model.
This is the fundamental mistake. The model is the easiest part of an AI system. The hard parts are the systems around the model: data pipelines, access controls, monitoring, escalation workflows, rollback procedures, logging, alerting, and the organisational processes that determine who owns what. These are governance problems, not machine learning problems.
We have seen this play out across dozens of engagements. A financial services firm spent eight months fine-tuning a document classification model that achieved 97% accuracy in testing. When they tried to deploy it, they discovered they had no way to log decisions for regulatory review, no process for handling the 3% of documents the model got wrong, and no plan for what happens when the model encounters a document type it has never seen before. The model was excellent. The system around it did not exist.
As we explored in our analysis of why AI governance is a design problem, not a compliance problem, the root cause is not technical incompetence. It is a framing error. Organisations treat AI as a technology project when it is actually a systems design project. The technology — the model, the API, the inference engine — is a component. The system includes the technology, the data, the humans, the processes, and the organisational structures that make it all work together safely and reliably.
Organisations treat AI as a technology project when it is actually a systems design project. The model is a component. The system includes the technology, the data, the humans, the processes, and the organisational structures that make it all work together.
Governed AI systems solve the 85% problem because they force you to answer the hard questions before you write a single line of model code. Who owns the data? Who approves high-stakes decisions? What does the audit trail look like? How do we roll back? How do we monitor for drift? These questions are boring compared to model architecture, but they are the questions that determine whether your AI project reaches production or dies in a sandbox.
We saw this firsthand when we inherited a marketing automation system where an AI model was automatically sending outreach emails based on lead scoring predictions. There was no audit trail or rollback mechanism, so when the model began misclassifying prospects the team could not trace why the system was behaving differently. The result was hundreds of poorly targeted emails sent within a few hours, and the company had to manually shut down the automation. Every problem in that system could have been prevented with basic governance — logging, confidence thresholds, and a rollback plan.
What governed AI systems look like in production
In production, governed AI systems log every input, score every decision with confidence levels, route high-stakes outputs to human reviewers, and maintain versioned rollback points across the entire pipeline. Abstract principles are useful, but they do not ship software. Here is what governance looks like when it is actually built into a running system.
Consider a document processing pipeline — the kind we build regularly at KORIX. The system ingests thousands of documents per day, classifies them by type, extracts key data fields, validates the extracted data against business rules, and routes the results to downstream systems. Without governance, this is a black box that occasionally produces errors nobody can explain.
With governance, the architecture looks fundamentally different.
At the ingestion layer, every document is logged with a unique identifier, timestamp, source, and hash. You can trace any output back to the exact input that produced it. Data validation rules reject malformed inputs before they reach the model, and rejected inputs are logged separately with the reason for rejection.
At the classification layer, the model assigns a category and a confidence score. Documents above the confidence threshold (say, 0.92) are auto-processed. Documents below the threshold are routed to a human review queue. The threshold is configurable and monitored — if the percentage of documents hitting the review queue spikes, that is an early signal of model drift or a change in document types.
At the extraction layer, the same pattern applies. Extracted fields are validated against expected formats and ranges. A field that falls outside expected parameters gets flagged. Critical fields — monetary amounts, dates, identification numbers — always get a secondary validation pass.
At the output layer, every processed document generates an audit record: what was extracted, what confidence scores were assigned, whether human review was triggered, who reviewed it (if applicable), and what the final output was. These records are immutable and retained according to the client’s compliance requirements.
The client’s team can do several things with this architecture that they could never do with an unstructured AI deployment. They can audit any decision. They can adjust confidence thresholds without retraining the model. They can identify patterns in the documents that get escalated to human review and use those patterns to improve the model. They can roll back to a previous model version if a new version performs worse. And they can demonstrate to regulators exactly how the system makes decisions.
This is not theoretical. This is what governed AI systems look like when they are designed correctly from day one. The additional engineering effort is modest — perhaps 20–30% more than an ungoverned system — but the difference in production reliability, maintainability, and trust is enormous.
As we discussed in our piece on designing AI systems that can be questioned, the ability to interrogate an AI system’s decisions is not a nice-to-have. It is the foundation of organisational trust in AI, and without it, adoption stalls regardless of how good the model is.
We built an AI lead qualification system where every automated decision had a human-in-the-loop approval checkpoint before leads were pushed into the CRM pipeline. During early deployment, the model started aggressively qualifying low-quality leads due to a temporary data issue from the marketing platform. Because the system had an approval checkpoint and audit logs, the operations manager flagged it immediately and we rolled back the model version before the sales team even noticed the error. That is governance in action — not a theoretical framework, but a system that catches problems before they cause damage.
The 5 pillars of a governed AI system
The five pillars of a governed AI system are data governance, decision ownership, human-in-loop checkpoints, observability, and rollback architecture. We use this five-pillar framework to design governance into every system we build. Each pillar addresses a specific failure mode that we have seen kill AI projects in production.
Pillar 1: Data governance
Every AI system is only as reliable as its data. Data governance means three things: the data is structured and validated before it reaches the model, the data is encrypted at rest and in transit, and the data lineage is traceable — you can always answer “where did this data come from and how was it transformed?”
In practice, this means building data validation layers that reject or flag data that does not conform to expected schemas. It means implementing encryption standards that meet your regulatory requirements. And it means maintaining a data catalogue that documents every data source, every transformation, and every access point.
The most common failure we see is organisations feeding unvalidated data into models and then blaming the model when outputs are wrong. The model is doing exactly what it was trained to do. The problem is that nobody validated the input.
Pillar 2: Decision ownership
Every decision an AI system makes — or recommends — must have a clear owner. Decision ownership answers three questions: who is accountable for this decision? Who has the authority to override it? And who gets notified when the decision is made?
This sounds like project management, and in a sense it is. But it is project management applied to automated decisions happening at scale. When an AI system processes 10,000 documents per day and makes classification decisions on each one, somebody needs to own those decisions collectively. That person needs the authority to adjust thresholds, pause processing, or escalate to leadership when something looks wrong.
Decision ownership maps directly to your organisational structure. In a regulated industry, the decision owner is often a compliance officer or risk manager. In a product context, it might be a product manager or engineering lead. The specific person matters less than the fact that the role is defined, documented, and understood.
Pillar 3: Human-in-loop checkpoints
Not every decision needs a human. But some do, and the system must know the difference. Human-in-loop checkpoints are the points in a workflow where the system pauses and waits for human approval before proceeding.
Designing effective checkpoints requires understanding two things: the cost of a wrong decision (financial, reputational, legal) and the confidence level of the model for that specific decision. High-cost, low-confidence decisions always need human review. Low-cost, high-confidence decisions can be automated. Everything in between is a judgment call that should be made explicitly and revisited regularly.
The biggest mistake we see is organisations setting up human-in-loop checkpoints and then overwhelming the human reviewers with volume. If your reviewers are processing hundreds of escalations per day, they are not reviewing — they are rubber-stamping. The checkpoint has become theatre. Effective human-in-loop design means calibrating the volume of escalations to the capacity and attention span of the reviewers.
We saw this in practice with a financial services firm that wanted to automate document analysis for loan applications. Every AI-generated recommendation had to be auditable for regulatory compliance and internal risk reviews. We built the system with decision logs, model version tracking, and human approval checkpoints so compliance officers could trace exactly how each recommendation was generated before final approval. Without those checkpoints, the system would have been unusable in a regulated environment — regardless of how accurate the model was.
Pillar 4: Observability
Observability is the ability to understand what your system is doing right now and what it did in the past. It has three components: dashboards that show real-time system health, alerts that fire when metrics deviate from expected ranges, and anomaly detection that identifies patterns humans might miss.
Good observability for an AI system goes beyond standard application monitoring. You need to track model-specific metrics: prediction confidence distributions, input data distributions (to detect drift), processing latency, escalation rates, and error rates by category. A sudden shift in any of these metrics is an early warning that something has changed — either in the data, the model, or the environment.
We build observability dashboards that answer three questions at a glance: is the system healthy? Is the model performing as expected? Are there any anomalies that require investigation? If your operations team cannot answer those three questions in under 30 seconds, your observability is insufficient.
Pillar 5: Rollback architecture
The final pillar is the one most organisations skip entirely: the ability to roll back when something goes wrong. Rollback architecture means maintaining versioned models, versioned decision logic, and versioned data pipelines so that you can revert to a known-good state without data loss or extended downtime.
In practice, this requires three capabilities. First, model versioning — every deployed model is tagged with a version, and previous versions are retained in a deployable state. Second, configuration versioning — every threshold, parameter, and rule is version-controlled alongside the model. Third, data pipeline versioning — if you change how data is preprocessed, you can revert that change independently of the model.
The value of rollback architecture becomes apparent the first time a model update causes a regression. Without rollback, the team scrambles to diagnose the issue, retrain or patch the model, and redeploy — a process that can take days or weeks. With rollback, the team reverts to the previous version in minutes, restoring service while they investigate the root cause on a parallel track.
Want Governance Built In From Day One?
Our 21-Day AI Pilot delivers a working governed system on your data — observable, auditable, and rollback-ready. Not a demo. A production system.
Explore the AI Pilot →How KORIX builds governed AI systems
KORIX builds governed AI systems by designing the governance architecture before selecting a model, writing a prompt, or building an interface — because bolting governance on later is three times harder. This is not a philosophical position — it is a practical one. We have learned, through painful experience, that retrofitting governance onto an existing AI system costs three times more in engineering effort than building it in from the start.
Every engagement begins with governance design. We map the decisions the AI system will make, classify those decisions by risk level, define the human-in-loop checkpoints, design the audit trail, and specify the rollback procedures. Only after this governance architecture is agreed upon do we move to model selection and system implementation.
This approach produces two immediate benefits. First, it surfaces the hard organisational questions early — who owns this system? who approves this decision? what happens when it fails? — before the team has invested months of engineering effort. Second, it creates a shared language between technical and non-technical stakeholders. The governance architecture becomes the document that everyone — engineers, compliance officers, business owners, executives — can point to and say “this is how the system works.”
Our 21-Day AI Pilot is specifically designed as a structured entry point for organisations that want to adopt AI with governance built in from the start. In 21 days, we take a real business process, build a governed AI solution around it, and hand it over to your team with full documentation. The pilot is not a demo — it is a production system, complete with audit trails, human-in-loop checkpoints, and rollback capabilities.
The pilot exists because we found that governance becomes real only when people can see it working on their own data, in their own environment, solving their own problems. Abstract governance frameworks gather dust. Working governed systems change minds.
Every pilot we run follows the five-pillar framework. By the end of the 21 days, the client has not just an AI system — they have a governed AI system they understand, can operate, and can extend. That is the difference between a proof-of-concept that dies and a system that compounds value over time.
One client paused during the demo when we showed them the audit dashboard that tracked every AI decision and model version change. Their operations lead said, “This is the first time we’ve seen an AI system we can actually control.” That moment shifted the conversation from experimenting with AI to confidently deploying it across more workflows. Governance is not a constraint — it is the thing that gives teams the confidence to scale.
Is your organisation ready for governed AI?
Your organisation is ready for governed AI if you have a specific measurable use case, clear data ownership, an operational owner, the ability to commit to a 21-day focused effort, and defined success criteria. Before investing in a governed AI system, it is worth asking whether your organisation has these foundations in place. Here are the questions we ask at the start of every engagement.
Do you have a specific, measurable business process you want to improve? “We want to use AI” is not a use case. “We want to reduce document processing time from 4 hours to 20 minutes while maintaining 99% accuracy” is a use case. Governed AI systems are built to solve specific problems. If you cannot define the problem precisely, you are not ready.
Do you know where your data lives and who owns it? Governance starts with data. If your data is scattered across systems with no clear ownership, you need to sort that out before you build an AI system on top of it. This does not mean your data needs to be perfect — it rarely is. But you need to know what you have, where it is, and who is responsible for it.
Do you have someone who will own the AI system operationally? An AI system without an operational owner is an orphan. It will not be monitored, it will not be maintained, and when it breaks, nobody will fix it. The operational owner does not need to be a machine learning engineer. They need to be someone with the authority and accountability to keep the system running, escalate issues, and make decisions about thresholds and configurations.
Can your organisation tolerate a 21-day focused effort? Building a governed AI system requires focus. Key stakeholders need to be available for design workshops, data access needs to be provisioned, and someone needs to be empowered to make decisions without routing everything through committee. If your organisation cannot commit that level of focus for three weeks, the project will drag for months.
Do you understand what “good” looks like? You need success criteria defined before you start. What accuracy level is acceptable? What processing speed do you need? What does the audit trail need to contain for your regulators? If you cannot define success, you cannot govern the system toward it.
If you answered yes to most of these questions, you are in a strong position to adopt governed AI. If you are unsure, our AI readiness assessment walks you through a more detailed evaluation.
Governed AI is not about slowing down adoption. It is about making adoption durable.
Governed AI systems do not slow adoption — they make it durable by ensuring every AI decision can be traced, questioned, and reversed. The organisations that will win with AI over the next decade are not the ones that moved fastest — they are the ones that built systems they could trust, audit, and improve over time. Governance is the architecture of that trust.
Recommended Reading
What is governed AI?
Governed AI is an AI system that is observable, human-in-loop, auditable, rollback-ready, and owned by your team. It means every decision the AI makes can be traced, questioned, and reversed. It is the structural difference between an AI project that delivers lasting value and one that stalls in a sandbox.
Why do 85% of enterprise AI projects fail?
Most fail because organisations focus on the model and neglect the systems around it — data pipelines, access controls, monitoring, escalation workflows, rollback procedures, and governance. These are systems design problems, not machine learning problems. The model is the easiest part.
What are the 5 pillars of governed AI?
The five pillars are: (1) Data governance — validated, encrypted, traceable data; (2) Decision ownership — clear accountability for every AI decision; (3) Human-in-loop checkpoints — high-stakes decisions require human approval; (4) Observability — real-time monitoring and anomaly detection; (5) Rollback architecture — versioned models, logic, and pipelines for instant revert.
How much extra does governance add to an AI project?
Building governance in from day one adds roughly 20–30% to the engineering effort. However, bolting governance onto an existing system later is approximately three times harder. Starting with governance is the more cost-effective approach. Our 21-Day AI Pilot includes full governance by default.
How do I know if my organisation is ready for governed AI?
You need five things: a specific, measurable business process to improve; knowledge of where your data lives and who owns it; an operational owner for the AI system; the ability to commit to a 21-day focused effort; and clearly defined success criteria. Take our AI readiness assessment for a detailed evaluation.