
Five AI architecture stacks ship roughly 95% of production AI workloads in service businesses in 2026: RAG-on-CRM, Slack-Agentic, Document AI on M365/SharePoint, Multi-Agent Orchestration, and Bespoke API Services. The single biggest predictor of project success is matching the stack to the use case on Day 1 — not the cleverness of the architecture or the popularity of the framework.
I've spent 19 years building software systems, the last several focused specifically on AI implementation for service businesses with 20-150 staff. In that time I've shipped or inherited deployments across all five of the stacks below — and I've seen each fail at least once when the wrong stack was forced onto the wrong use case. This article is the architecture playbook I wish someone had written before I had to learn it the expensive way.
The framing this article disagrees with is the LinkedIn AI-influencer framing — that the answer is always the most complex multi-agent architecture, that everyone should be using LangGraph, that you need a vector database, knowledge graph, agent orchestrator, observability stack, and your own fine-tuned model. For 95% of service-business AI workloads in 2026, the production stack is much simpler than the trending discourse suggests. Pick on use case fit. Pick on what your operations team can actually run.
The Stack-Fit Test (Pick Before You Build)
Before walking through the five stacks, ask three questions of your use case. The answers determine the stack. Try to skip these and you'll spend three months building the wrong architecture.
- Where does the user already work? If users live in Salesforce, the stack lives in Salesforce. If users live in Slack, the stack lives in Slack. If users live in document review, the stack lives in document workflows. The right stack meets users where they are — it does not ask them to adopt a new interface.
- Does the AI need to take actions, or just answer questions? Answer-only = RAG-only. Action-taking = Agentic. The distinction matters for governance and rollback design.
- How many distinct sub-tasks does the workflow have, and are they sequential or independent? 1-2 sub-tasks sequential = single agent. 3+ sub-tasks with independent specialisation = multi-agent. Don't over-engineer.
Andrew Ng has been making this point for years: the gap between "AI works in a notebook" and "AI works in production" is roughly 100× the engineering effort, and almost all of that effort is glue code, governance, and integration — not the model itself. Cassie Kozyrkov, former Chief Decision Scientist at Google, frames the architecture-selection problem similarly: "The bottleneck is not the AI technology. The bottleneck is knowing which problem to give it." Picking the wrong stack is just a specific case of giving the AI the wrong problem.
Bain's 2026 research on phasing agentic AI into production reaches a similar conclusion from a different angle: the firms that ship to production are the ones that pick a deliberately simpler architecture than the latest trend, then add complexity only when the business case justifies it. MIT NANDA's 2025 State of AI Report backs this with hard data: only 5% of AI workflow projects reach production, and the failure mode is almost always architecture-mismatch (a workflow forced into the wrong stack) rather than model performance. Atlassian's 2026 State of Product survey separately found 46% of teams cite integration as the single biggest barrier — and integration is exactly what stack selection determines.
Stack 1 — RAG-on-CRM (HubSpot, Salesforce)
What it is: A retrieval-augmented generation layer wired directly into your CRM, giving sales and customer-success agents an AI assistant that knows the full account history, recent communications, deal stage, and product context.
Components: Vector database (Pinecone, Weaviate, or Postgres+pgvector) ingesting CRM records, communication logs, knowledge base, and product documentation. Embedding model (OpenAI ada-002 or open-source equivalent). LLM for generation (GPT-4 class for accuracy-sensitive use cases, Claude Sonnet or open-weight equivalent for cost-sensitive). Wrapper application surfacing the agent inside the CRM UI itself (Salesforce Lightning component, HubSpot card extension, or browser extension).
Time to production: 2-4 weeks for the first deployed agent, assuming the CRM data is reasonably clean.
Best for: Sales-AI assistants that draft emails, summarise account context, suggest next steps. Customer-success agents that surface at-risk accounts and recommend interventions. Lead-qualification scoring with a human-readable rationale.
The cliff: Performance degrades sharply if your CRM data is inconsistent, duplicated, or missing context. Atlan's 2026 RAG architecture guide notes that approximately 60-70% of RAG project effort is data preparation, not retrieval design. If your CRM is a mess, fix the data before building the agent.
Real-world example: A B2B services firm we worked with deployed a Salesforce-native lead-qualification agent that produced a fit-and-readiness score for every inbound lead within 90 seconds of capture. The deployment shipped in 19 days — but the prerequisite data cleanup (de-duplicating accounts, standardising industry tags, filling missing firmographic fields) took a separate three-week prep phase before that.
Stack 2 — Slack-Agentic (Internal Ops)
What it is: AI agents deployed inside Slack (or Microsoft Teams) as conversational entities that route work, summarise incoming requests, run reports, and trigger workflows. The user interacts in Slack; the agent acts in connected systems.
Components: Slack bot (or Teams bot) framework. Tool-calling-capable LLM (GPT-4o, Claude 3.5+, function-calling-enabled). Connector layer to internal systems (Zapier-as-bridge, n8n, or direct API integrations). State management via Slack thread context plus a lightweight session store. Audit log capturing every agent decision plus the data inputs that produced it.
Time to production: 2-3 weeks for the first deployed agent.
Best for: Internal operations: AI agents that summarise daily ops reports, route customer escalations to the right team, draft status updates from across multiple sources, schedule follow-ups, or pull cross-system reports on demand.
The cliff: Slack-Agentic doesn't scale well past ~10-15 active agents in the same workspace because attention management becomes hard for users. After that point, you need a dedicated front-end interface — at which point you've outgrown Stack 2.
Real-world example: A 60-person operations team we worked with deployed a Slack-native triage agent that automatically classified incoming requests across three internal queues and posted a daily summary of the top-priority items. The team's email-response time on internal requests dropped meaningfully within the first month. Total deployment: 16 days.
Stack 3 — Document AI on M365/SharePoint
What it is: Extraction and classification pipelines that ingest documents (contracts, invoices, applications, claims forms), extract structured data, validate against business rules, and feed the extracted output into downstream workflows.
Components: Document ingestion pipeline (M365 connector, SharePoint Graph API, or direct file-drop folder). OCR layer (Azure Document Intelligence, Google Document AI, or open-source via Tesseract+Donut). LLM-based extraction with structured output validation (Pydantic schemas, JSON Schema enforcement). Audit trail capturing every extraction, every validation result, and every human override. Downstream workflow integration (CRM update, invoicing system, compliance reporting).
Time to production: 4-6 weeks because data preparation, schema design, and edge-case handling dominate the engineering effort.
Best for: Service businesses with high document volume — legal, accounting, professional services, financial services, insurance, healthcare administration. Especially valuable in regulated industries where audit trails are required.
The cliff: Edge cases. The 95% of documents your extraction agent handles cleanly are easy. The 5% it fails on cause downstream chaos if not flagged for human review with a clear rationale. Atlassian's 2026 State of Product survey found 46% of teams cite integration as the single biggest barrier to scaling AI automation — and document AI is where integration breaks first.
Real-world example: An operations-heavy services client manually processing several thousand documents monthly deployed a Document AI extraction system that auto-structured the data into their downstream reporting workflow. Manual processing time dropped meaningfully and accuracy improved on its own. The deployment took six weeks total — the extraction model itself was three weeks; the schema design and the downstream integration took the other three.
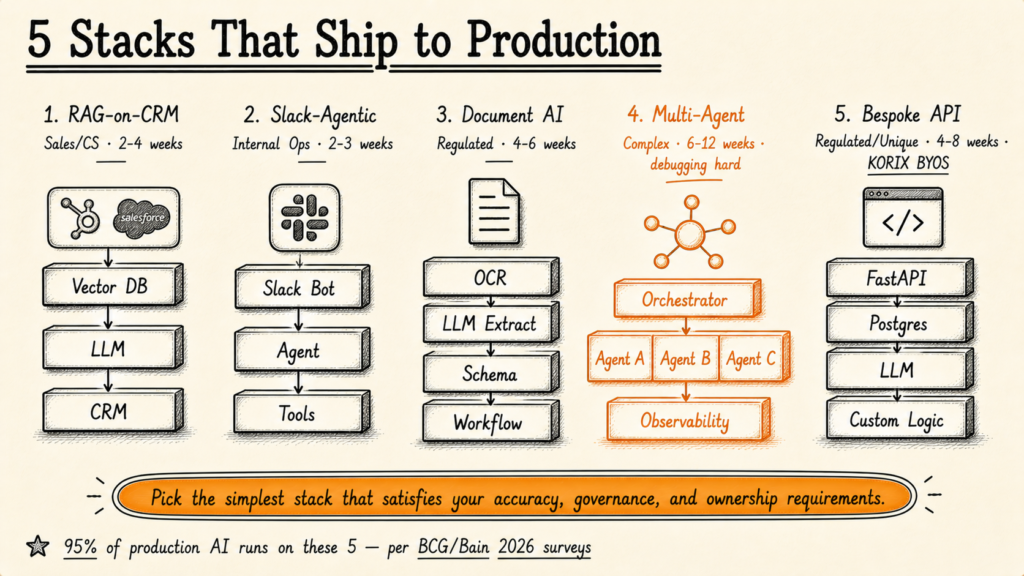
Stack 4 — Multi-Agent Orchestration (LangGraph + n8n)
What it is: A workflow engine running multiple specialised agents that hand off to each other to complete complex multi-step processes. Each agent has a defined role (researcher, analyst, writer, reviewer); the orchestration layer manages state, retries, and failure handling.
Components: Orchestration framework (LangGraph for code-first; n8n with custom nodes for visual; AutoGen or CrewAI for agent-conversation patterns). Per-agent prompts and tool sets. Shared state management. Inter-agent message routing. Comprehensive observability layer (LangSmith, Langfuse, or homegrown tracing). Retry and fallback logic for each agent.
Time to production: 6-12 weeks. Multi-agent systems are powerful but introduce coordination complexity that single-agent systems don't have. Plan for at least one major architecture revision after the first deployed version.
Best for: Complex workflows with genuinely independent sub-tasks: market research → competitor analysis → strategic recommendation; document review → risk classification → escalation routing; sales-cycle automation across multiple specialised agents (qualification → research → outreach → handoff).
The cliff: Debugging. When a multi-agent system fails, the failure can be in any of N agents, in the orchestration logic, in the inter-agent communication, or in the underlying tool calls — and tracing which usually requires a dedicated observability stack and engineering capacity to interpret it. Most service businesses are not the right buyer for Stack 4.
Real-world example: A B2B research firm we advised deployed a four-agent pipeline (researcher, analyst, writer, editor) producing first-draft research reports from a topic brief. The system shipped in 11 weeks — the first 8 weeks built the agents; the last 3 weeks were observability, retry logic, and human-review checkpoints.
Stack 5 — Bespoke API Service Layer
What it is: A purpose-built API service that wraps an LLM with custom business logic, validation, and integration code. Not a platform, not a no-code tool — code you write because no platform fits the use case.
Components: Application framework (FastAPI is the common pick in 2026, with Node.js/Express as the runner-up). Database (Postgres with pgvector for embedded RAG). LLM API integration (OpenAI, Anthropic, or self-hosted via vLLM). Caching layer (Redis). Authentication and authorisation. Comprehensive monitoring and alerting. Deployment infrastructure (containerised, often on AWS Fargate, GCP Cloud Run, or Hostinger VPS for cost-sensitive deployments).
Time to production: 4-8 weeks for the first production endpoint, depending on integration complexity.
Best for: Use cases where no platform fits: highly specific business logic, unusual data shapes, regulated environments where the buyer must own every line of code, or scale economics that make platform fees uneconomic. KORIX BYOS deployments typically land in Stack 5 — bespoke services wired directly into the buyer's existing software estate.
The cliff: Engineering capacity. Bespoke API services are the right answer when no platform fits, but you (or your vendor) own everything from monitoring to security patching. Most teams underestimate the ongoing ops cost by a factor of two or three. BCG's 2026 AI Value Capture research finds that organisations capturing the most AI value are not the ones with the most sophisticated infrastructure — they are the ones with the clearest process definitions and the tightest feedback loops between AI output and human review. That's true at Stack 5 as much as anywhere else.
Real-world example: A regulated financial services firm needed AI document analysis with full audit trails, model version pinning, and human approval checkpoints — none of which the off-the-shelf platforms supported in the way the firm's compliance officers required. The bespoke deployment took eight weeks total: four for the extraction service itself, four for the audit infrastructure and compliance reporting integration. The firm now owns every line of code and continues to extend the system internally.
Want a Realistic Plan for Your Project?
No sales pitch. We will give you an honest read on what your situation actually needs, what it should cost, and whether AI is even the right tool here.
Book a Discovery Call →Decision Table — Match the Stack to the Use Case
| Use case shape | Recommended stack | Time-to-prod | Effort signal |
|---|---|---|---|
| Sales/CS assistant with account context | Stack 1 — RAG-on-CRM | 2-4 weeks | Data prep is 60-70% |
| Internal ops triage / summarisation | Stack 2 — Slack-Agentic | 2-3 weeks | Caps at ~15 agents |
| Document extraction at volume | Stack 3 — Document AI on M365 | 4-6 weeks | Edge cases dominate |
| Complex multi-step workflow | Stack 4 — Multi-Agent Orchestration | 6-12 weeks | Debugging is the hard part |
| Regulated / unique business logic | Stack 5 — Bespoke API Service | 4-8 weeks | Ops cost is real |
Three Architecture Failures I've Inherited
Pattern recognition from inheriting and rebuilding production AI systems. Names disguised; lessons exact.
Failure 1: The multi-agent system that should have been a single agent
A B2B services firm deployed a four-agent pipeline for what was, in retrospect, a sequential single-agent workflow. The first agent ran research; the second classified; the third drafted; the fourth reviewed. The workflow could have been a single agent calling four tools in sequence. The four-agent design added inter-agent message routing, four separate observability surfaces, and four separate failure modes. Eighteen months in, the team rebuilt as a single agent and shipped 60% faster on every subsequent change.
Lesson: Multi-agent systems are not a default — they're an answer to a specific question (genuinely independent specialised sub-tasks). If your sub-tasks are sequential, a single agent with tool-calling is almost always the right architecture.
Failure 2: The CRM agent that ignored data quality
A sales-AI assistant deployed against a Salesforce instance that had been growing for eight years without consistent data hygiene. Account records duplicated. Industry tags inconsistent. Communication logs missing for accounts older than three years. The agent shipped on time, but its outputs were misleading enough that the sales team stopped trusting it within a month. The fix was a six-week data-quality remediation programme that should have been the first phase of the original engagement, not a remedial follow-up.
Lesson: RAG systems amplify the quality of the underlying data — both the good and the bad. If your data is messy, the agent will be confidently wrong. Fix the data foundation before deploying the agent layer.
Failure 3: The bespoke service that should have used a platform
A mid-market firm built a fully custom API service for what turned out to be a very common workflow that any of three platforms (Zapier, Make, or n8n) would have handled in two weeks. The bespoke approach took ten weeks, cost five times more than the platform alternative, and required ongoing engineering ops the firm hadn't budgeted for. Two years later, the firm migrated the workflow to n8n self-hosted and ran the same logic at a fraction of the operational cost.
Lesson: Bespoke is the right answer when no platform fits. It is the wrong answer when a platform would fit but the team has internal resistance to "using a tool". Validate the use case against existing platforms before committing to bespoke.
Where to Start
For a service business with 20-150 staff deploying its first production AI workload, the answer is almost always Stack 1 (RAG-on-CRM) or Stack 2 (Slack-Agentic). Both ship in two to three weeks, have well-understood failure modes, and produce measurable ROI inside the first quarter.
For high document volume in regulated industries, Stack 3 (Document AI on M365/SharePoint) is the clear right call.
Stacks 4 and 5 are the right call for specific patterns — complex multi-agent workflows or regulated environments where no platform fits — but neither should be a starting architecture for a team's first production AI deployment. Start with Stack 1, 2, or 3, prove the workflow, then graduate to a more complex stack only when the business case justifies the additional engineering capacity.
For the broader question of "platform vs bespoke", our breakdown of the 8 best AI workflow tools and where each one breaks covers the platform side. For "build vs buy" within a stack, see Build vs Buy. For governance design from Day 1, Governed AI is the longer treatment.
If you want to validate the right stack for your specific use case before committing, KORIX BYOS exists for exactly this purpose — bespoke deployment scoped to a single workflow, shipped in 21 days. The 21-Day AI Pilot is the structured engagement that runs the diagnostic plus the deployment in one bounded scope.
KORIX defines the production stack as the simplest architecture that satisfies the use case's accuracy, latency, governance, and ownership requirements — not the most sophisticated framework on the market. The buyers who win in 2026 are the ones who pick a deliberately simpler architecture than the trending discourse suggests, then add complexity only when the business case actually demands it.
Continue learning
- AI Workflow Automation for Service Businesses (2026 Guide)
- Agent Deployment as a Service: The 2026 Model That Replaced AI Consulting
- Top AI Implementation Companies in India (2026)
- AI Consultancy vs AI Deployment: 2026 Buyer's Guide
- Governed AI Implementation Without the 6-Month Delay
- AI Governance vs Governed AI
Five architectures ship 95% of production AI in 2026. Pick the stack that fits the use case — not the one that's trending on LinkedIn.
RAG-on-CRM ships customer-facing agents fastest. Slack-Agentic wins for internal ops. Document AI on M365/SharePoint dominates regulated extraction. Multi-Agent Orchestration handles complex multi-step workflows. Bespoke API services exist when no platform fits. Each stack has a specific time-to-production, cost shape, governance posture, and failure mode. The single biggest predictor of project success is matching the stack to the use case on Day 1 — not the cleverness of the architecture, the popularity of the framework, or the size of the vendor.
Continue learning —
go deeper.
What is the most common AI architecture in production in 2026?
Hybrid RAG (Retrieval-Augmented Generation) is the production baseline for most enterprises in 2026, balancing accuracy, cost, and governance. RAG works by retrieving relevant context from a vector database before generating a response, which keeps the AI grounded in your specific data rather than relying on the model's pre-training. The next most common is Agentic-on-Workspace (Slack, Microsoft Teams, or chat-based interfaces with tool-calling agents), followed by Document AI pipelines for extraction and classification. More complex architectures like Graph RAG or hierarchical multi-agent systems are used only when reasoning depth genuinely requires them — not as the default.
Should I use a multi-agent system or a single agent for my AI workflow?
Start with a single agent. Multi-agent systems are powerful but introduce coordination complexity, debugging difficulty, and cost overhead that most service-business use cases don't justify. The rule we apply at KORIX: if a single agent with tool-calling and a RAG layer can handle the workflow within a 60-second response window, use the single agent. Multi-agent systems become the right choice when the workflow has genuinely independent sub-tasks (e.g., research + analysis + writing in parallel), when one specialised model significantly outperforms a generalist on each sub-task, or when the orchestration logic itself needs to be auditable and inspectable. Most production deployments in 2026 are still single-agent + RAG + tool-calling.
How long does it take to deploy each AI stack to production?
Realistic timelines vary sharply by stack. RAG-on-CRM (HubSpot, Salesforce): 2-4 weeks for a single agent with a clean knowledge base. Slack-Agentic (internal ops): 2-3 weeks for the first deployed agent. Document AI on M365/SharePoint: 4-6 weeks because data preparation dominates. Multi-Agent Orchestration: 6-12 weeks due to inter-agent coordination complexity. Bespoke API service layer: 4-8 weeks for the first production endpoint. The KORIX 21-Day Pilot is structured around the first three stacks, which represent roughly 80% of service-business use cases.
What is the difference between RAG and Agentic AI?
RAG (Retrieval-Augmented Generation) is a technique where an AI model retrieves relevant context from your knowledge base before generating a response. It does not take actions — it generates text. Agentic AI is a system pattern where the AI can take actions: call APIs, write to databases, send emails, modify CRM records. Most production deployments combine both: an agent uses RAG to ground its reasoning, then takes actions through tool-calling. The distinction matters because RAG-only systems cannot break things — they generate text only — while Agentic systems can. That changes the governance and rollback posture significantly.
Which AI stack is best for service businesses with 20-150 staff?
For most service businesses in this size range, RAG-on-CRM and Slack-Agentic are the two stacks that produce the highest ROI fastest. RAG-on-CRM gives sales and customer-success teams an AI assistant that knows your full account history. Slack-Agentic gives ops and management AI agents that route work, summarise incoming requests, and trigger workflows from within the chat interface the team already uses. Document AI is the third most common, particularly for service businesses with high document volume (legal, accounting, professional services). Multi-agent and bespoke API stacks are rarely the right starting point at this scale — start with RAG-on-CRM, prove the workflow, then consider scaling architectures.