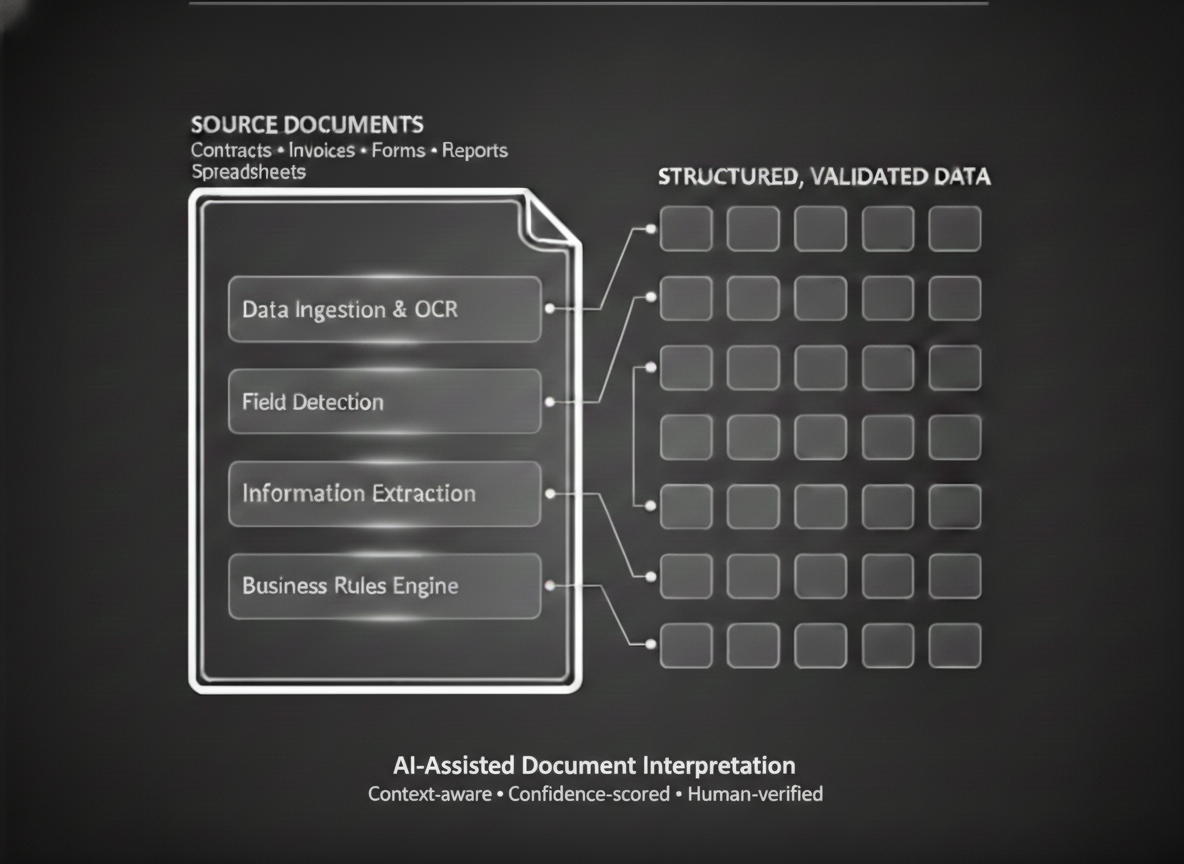
A growing organisation relied on high volumes of documents—contracts, forms, reports, and records—locked in PDFs, scans, and legacy formats. Manual data extraction slowed operations and introduced avoidable risk at scale.
Leadership wanted to digitise documents intelligently, not just run basic OCR, while improving accuracy, traceability, and enterprise‑grade reliability for downstream systems.
This work focused on intelligent document digitisation and AI‑powered information extraction to turn unstructured files into structured, validated data that could flow cleanly into core enterprise platforms.
Designed for operations, compliance, and technology leaders in document‑heavy organisations in US, UK and other growing markets.
Challenges in Enterprise Document Digitisation
High dependency on manual data entry
Teams spent excessive time extracting and validating information from documents, limiting scalability and increasing operational cost. Existing OCR and document processing approaches produced raw text without sufficient context, making validation and downstream use unreliable.
02
Unstructured and inconsistent document formats
Documents varied widely in layout, quality and structure, making rule-based automation brittle and error-prone.
03
Data accuracy and compliance risk
Even small extraction errors had downstream implications for reporting, billing or regulatory compliance.
04
Low trust in traditional OCR systems
Previous OCR attempts produced raw text without context, requiring heavy rework and limiting adoption across teams.
These challenges are common for growing teams in India and globally who still depend on PDFs, scans, and legacy formats for critical business data.
Have a similar document-heavy workflow and want to see what an AI document intelligence system could look like in your context?
Talk to an AI systems expert
Talk to an AI systems expert
AI-Driven Approach to Document Digitisation & Extraction
Document intelligence, not basic OCR
We designed the solution to understand document structure, context, and intent—identifying fields, relationships, and exceptions.
02
Multi-stage validation pipelines
Extracted data passed through confidence scoring, rule checks, and human verification for critical fields.
03
Schema-driven extraction models
Instead of generic extraction, models were aligned to business-defined schemas, ensuring relevance and consistency.
04
Seamless integration with existing systems
Structured outputs were designed to flow directly into internal platforms, dashboards, and reporting tools.
This AI-driven approach helped the organisation move from ad‑hoc document handling to a governed, enterprise-ready document intelligence system that can evolve with the business.
Outcomes of Intelligent Document Processing
Faster document processing cycles
Turnaround time for document handling reduced significantly, enabling near-real-time availability of structured data.
02
Higher accuracy with reduced rework
Confidence-aware extraction improved reliability and reduced manual correction effort.
03
Improved operational visibility
Previously locked information became searchable, auditable, and usable across teams.
04
Scalable foundation for enterprise automation
The system enabled future enterprise automation initiatives without re-engineering document workflows.
Together, these outcomes turned document-heavy operations into a reliable, scalable system—ready for new use cases, new teams, and growth across regions.
What These Engagements Share
Clear system boundaries before execution
Systems were defined upfront – what they touch, what they ignore, and who owns each part – before any automation or AI was deployed.
02
Trade-offs made explicit rather than implicit
Decisions about speed, accuracy, effort, and cost were documented clearly so teams understood what they were gaining and what they were giving up.
03
Documentation that supported future iteration
The solution was documented as a living system – assumptions, constraints, and workflows – so future teams could extend it without reverse‑engineering everything.
04
Emphasis on long-term sustainability over short-term gains
Architecture, data flows, and ownership were designed to survive new use cases, not just to hit the first milestone or demo.
This consistency is deliberate: it lets teams grow without re-solving the same structural problems in every new project.
How We Define Success
Remain reliable under increasing load
The system keeps performing as document volumes, users, and edge cases grow, without constant firefighting or fragile patches.
02
Support better decision-making
The outputs are trustworthy, explainable, and timely enough that people can make stronger decisions with less manual digging.
03
Reduce operational complexity
Processes become simpler to run, monitor, and hand over, rather than adding hidden workflows and brittle manual checks.
04
Scale without rework, aligned with business objectives
New use cases and integrations can be added on top of the existing system, without throwing away core components or drifting away from business goals.
These factors decide whether the solution stays useful long after the initial delivery.
Tech Stack
Backend
Python (FastAPI) services for document workflows and validation logic
02
Document processing
Cloud OCR and document intelligence (Azure Form Recognizer / Google Document AI–class services) for high‑volume, multi‑format documents
03
AI & extraction
Transformer‑based NLP models and schema‑driven extraction pipelines to map unstructured text into trusted, structured fields
04
Data & storage
PostgreSQL for structured records, object storage for raw and processed files, Redis for caching high‑frequency lookups
04
Integrations
REST/JSON APIs into internal systems (line‑of‑business tools, reporting, and audit systems)
05
Infrastructure & operations
Containerised services (Docker) deployed on major cloud providers with monitoring, logging, and alerting for production use
06
Quality & testing
Automated tests for core services and validation logic, plus monitoring to catch anomalies and regression issues early
Together, this stack gives the client a robust, cloud-native
document intelligence system that scale to new formats, volumes, and
workflows without constant re-engineering.
FAQ
FAQs about intelligent document digitisation
01 What types of documents can this system handle?
The system is designed for high-volume business documents such as contracts, forms, invoices, reports, and operational records in PDFs, scans, and common office formats. It can be adapted to mixed layouts and templates as long as there is a consistent underlying structure.
02 How is this different from basic OCR?
Basic OCR only converts images or PDFs into raw text. This system goes further by understanding document structure, mapping fields into business-defined schemas, applying validation rules, and routing low-confidence fields to human review so the outputs are ready for downstream systems.
03 Do we need perfectly standardised document templates to get value?
No. While cleaner, more consistent templates help, the solution is built to handle variation in layouts and quality. Part of the work involves designing schemas and extraction strategies that tolerate real-world inconsistency while still keeping validation and governance in place.
04How does the system ensure accuracy and compliance?
Extracted data goes through confidence scoring, rule-based checks, and human verification for critical fields. Audit logs, traceability, and clear exception handling mean you can see how a value was produced and who approved it before it reaches core systems.
05Can this document intelligence system integrate with our existing tools?
Yes. The system is designed to push structured outputs into your existing line-of-business tools, reporting environments, and data stores using APIs and standard formats, so you don’t have to replace your current platforms to benefit.
The system is designed for high-volume business documents such as contracts, forms, invoices, reports, and operational records in PDFs, scans, and common office formats. It can be adapted to mixed layouts and templates as long as there is a consistent underlying structure.
Basic OCR only converts images or PDFs into raw text. This system goes further by understanding document structure, mapping fields into business-defined schemas, applying validation rules, and routing low-confidence fields to human review so the outputs are ready for downstream systems.
No. While cleaner, more consistent templates help, the solution is built to handle variation in layouts and quality. Part of the work involves designing schemas and extraction strategies that tolerate real-world inconsistency while still keeping validation and governance in place.
Extracted data goes through confidence scoring, rule-based checks, and human verification for critical fields. Audit logs, traceability, and clear exception handling mean you can see how a value was produced and who approved it before it reaches core systems.
Yes. The system is designed to push structured outputs into your existing line-of-business tools, reporting environments, and data stores using APIs and standard formats, so you don’t have to replace your current platforms to benefit.
